Facebook公布最新AI成果:如何理解真实世界3D对象

开发对真实世界有着进一步理解的系统
(映维网 2019年11月01日)为了解释周围的世界,AI系统必须理解三维视觉场景。这种需求不仅只局限于机器人技术,同时包括导航,甚至是增强现实应用。即便是2D照片与视频,所描绘的场景和对象本身都属于三维。真正智能的内容理解系统必须能够视频中识别出杯子旋转时的把手几何形状,或者识别出对象是位于照片的前景还是背景。
日前,Facebook公布了多项能够推进3D图像理解的AI研究项目。虽然不尽相同,但互为补充。正在国际计算机视觉大会(International Conference on Computer Vision)进行演示的项目涉及一系列的用例和情形,包含不同种类的训练数据和输入。
- Mesh R-CNN是一种新颖的,先进的解决方案,可以通过各种现实世界2D图像预计最精确的3D形状。这个方法利用了Facebook的Mask R-CNN框架进行对象实例分割,其甚至可以检测诸如凳脚或重叠家具等复杂对象。
- Facebook指出,通过利用Mesh R-CNN的替代和补充方法C3DPO,他们是第一个通过解释3D几何形状而在三个基准上成功实现非刚性形状的大规模3D重建,对象类别涉及14种以上。需要注意的是,团队仅使用2D关键点来实现这一目标,零3D注释。
- Facebook提出了一种新颖的方法来学习图像与3D形状之间的关联,同时大大减少了对含注释训练示例的需求。这使得团队更接近于开发出能够为更多种类对象创建3D表示的自我监督系统。
- Facebook团队同时开发了一种称为VoteNet的新颖技术,其可以利用LIDAR或其他传感器的3D输入执行对象检测。尽管大多数传统系统都依靠2D图像信号,但这个系统完全基于3D点云。与以前的研究相比,它可以实现更高的精度。
这项研究的基础包括:利用深度学习来预测和定位图像中对象的最新进步,以及用于3D形状理解的全新工具和架构(如体素,点云和网格)。计算机视觉领域已经扩展到各种各样的任务,但3D理解将在支持AI系统进一步理解现实世界和执行相关任务方面发挥核心作用。
1. 以高精度预测非约束遮挡对象的3D形状
诸如Mask R-CNN这样的感知系统是理解图像的强大通用工具。但由于它们是根据2D数据进行预测,所以其忽略了世界的3D结构。利用2D感知技术的进步,Facebook设计了一种3D对象重建模型,可以根据非约束的真实世界图像预测3D对象形状,包含具有一系列光学挑战的图像(如具有遮挡,杂波和各种拓扑的对象)。将第三维带到对象检测系统,同时实现对复杂情况的稳定增加工作,这要求更为强大的工程能力,而当下的工程架构阻碍了所述领域的发展。
Mesh R-CNN根据输入图像预测里面的对象实例,并推断其3D形状。为了捕获几何形状和拓扑的多样性,它首先预测粗略体素,将其精化并进行精确的网格预测。
为了应对挑战,Faceboook团队通过网格预测分支增强了Mask R-CNN的2D对象分割系统,并构建了Torch3d(Pytorch库,其中包含高度优化的3D运算符)以实现所述系统。Mesh R-CNN利用Mask R-CNN来检测和分类图像中的各种对象。然后,它使用新颖的网格预测器来推断3D形状(所述预测器由体素预测和网格细化的混合方法组成)。在预测精细3D结构方面,这个两步过程实现了比以前更高的精度。通过支持复杂操作的高效,灵活和模块化实现,Torch3d能够帮助实现这一点。
他们利用Detectron2来实现最终的系统,其使用RGB图像作为输入并同时检测物体和预测3D形状。与Mask R-CNN使用监督学习来实现强大的2D感知类似,Facebook的新颖方法使用完全监督学习(成对的图像和网格)来学习3D预测。为了进行训练,团队使用了由10000对图像和网格组成的Pix3D数据集,而这比通常包含数十万个图像与对象注释的2D基准要小得多。
Facebook用两组数据集评估了Mesh R-CNN,而他们均取得了亮眼的结果。对于Pix3D数据集,Mesh R-CNN是第一个能够同时检测所有类别对象,并在各种杂乱无章的家具场景中预计完整3D形状的系统。先前的工作重点是在完美裁剪的,无遮挡的图像中评估模型。对于ShapeNet数据集,体素预测和网格细化的混合方法的表现要比先前的研究提升7%。
Mesh R-CNN的系统综述,Facebook用3D形状推断强化了Mask R-CNN
精确预测和重建非约束场景形状是迈向增强虚拟现实和其他新型体验的重要一步。尽管如此,与为2D图像收集注释数据相比,为3D图像收集注释数据要更加复杂和耗时,所以3D形状预测的数据集发展相对滞后。所以,Facebook正在探索不同的方法来利用监督学习和自我监督学习来重建3D对象。
相关论文:Mesh R-CNN完整论文
2. 用2D关键点重建3D对象类别
对于无法利用网格对象和相应图像进行训练,而且无需完全重建静态对象或场景的情况,Facebook开发了一种替代方法。全新的C3DPO(Canonical 3D Pose Networks)系统可以对3的D关键点模型进行重建,并通过更广泛的2D关键点监督来实现先进的重建结果。C3DPO能够以适合大规模部署的方式来帮助你理解对象的3D几何形状。

C3DPO根据检测到的2D关键点来为一系列对象类别生成3D关键点,能够精确区分视点变化和形状变形。
追踪对象类别特定部分(如人体关节或小鸟翅膀)的2D关键点提供了有关对象几何形状及其形状变形或视点变化的完整线索。生成的3D关键点十分有用,如用于3D面容和全身网格的建模,从而为VR构建更逼真的虚拟化身图形。与Mesh R-CNN相似,C3DPO使用非约束图像来重建3D对象。
C3DPO是第一种能够用数千个2D关键点来重建包含数十万个图像的数据集的方法。Facebook针对三种不同的数据集,14种以上不同的非刚性对象类别实现了先进的重建精度。相关代码已经托管至GitHub 。
Facebook的模型包含两个重要的创新。首先,给定一组单目2D关键点,这个全新的3D重建网络将预测相应camera视点的参数以及3D关键点位置。其次,Facebook提出了一种名为Canonicalization的新颖正准化技术(其包括一个第二辅助深度网络)。所述技术解决了因分解3D视点和形状而带来的歧义。这两项创新使得Facebook团队能够实现比传统方法更优秀的统计模型。
原来无法实现这种重建,这主要是因为以前基于矩阵分解的方法的存储限制。与Facebook的深度网络不同,所述方法不能在“小批量”状态下运行。以前的方法通过利用多个同时出现的图像,并建立瞬时3D重建之间的对应关系来解决变形建模问题,而这需要特殊实验室中专门研发的硬件。C3DPO带来的高效率使得在不使用硬件进行3D捕捉的情况下实现3D重建成为可能。
相关论文:C3DPO的完整论文。
3. 从图像采集中学习像素到表面映射
Facebook的系统学习了一个参数化卷积神经网络(CNN),它将图像作为输入并预测每个像素的正准表面映射,其可以说明模板形状的相应位置点。2D图像和3D形状之间的正准表面映射的相似着色暗示了对应关系。
Facebook进一步减少了开发通用对象类别3D理解所需的监督程度。他们介绍了一种可以通过近似自动实例分割来利用未注释图像集合的方法。Facebook没有明确预测图像的基础3D结构,而是解决了将图像像素映射到3D形状类别模板表面的补充任务。
这种映射不仅允许团队能够在3D形状类别的背景下理解图像,而且可以归纳相同类别对象之间的对应关系。例如,对于你在左侧图像中看到的高亮鸟喙,Facebook可以轻松地在右侧图像定位相应的点。

这可以实现的原因是,Facebook能够直观地理解实例之间的共同3D结构。将图像像素映射到正准3D表面的新颖方法同时为Facebook的学习系统带来了这项功能。当评估所述方法在各个实例之间传输对应关系的准确性时,其结果比原来的自我监督方法(不利用任务的底层3D结构)高出两倍。
Facebook的关键见解是,像素到3D表面的映射可以与逆操作(从3D到像素)配对,从而完成一个循环。Facebook团队的新颖方法可实现这个目的,并且可以利用检测方法的近似分割和无注释的,免费的,公开可用的图像集进行学习。Facebook的系统可以直接使用,并与其他自上而下的3D预测方法结合,从而提供对像素级3D的补充理解。相关代码已经托管至GitHub 。
如视频中汽车颜色一致性所表明,Facebook的系统为运动和旋转对象产生了不变的像素嵌入。这种一致性超出了特定的实例,并且在需要理解对象之间共性的情况下十分有用。
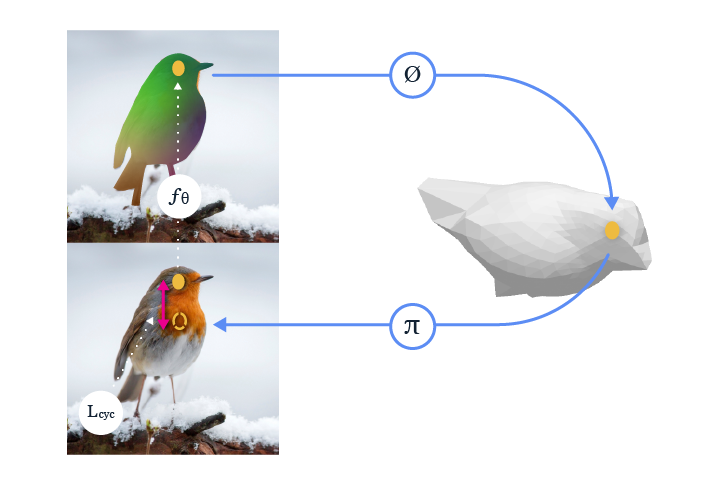
Facebook不是直接学习两个图像之间的2D到2D对应关系,而是学习2D到3D对应关系,并确保与3D到2D重投影的一致性。这种一致循环可用作学习2D到3D对应关系的监督信号。
例如,如果要训练系统学习椅子就座的正确位置或茶杯握持的正确位置,当系统下次需要理解如何就座另一张椅子或如何握持另一个茶杯时,这种表示就十分有用。这种任务不仅可以帮助你加深对传统2D图像与视频内容的理解,同时可以通过转移对象表示来增强AR/VR体验。
相关论文:正准表面映射论文
4. 提升当前3D系统的对象检测基础
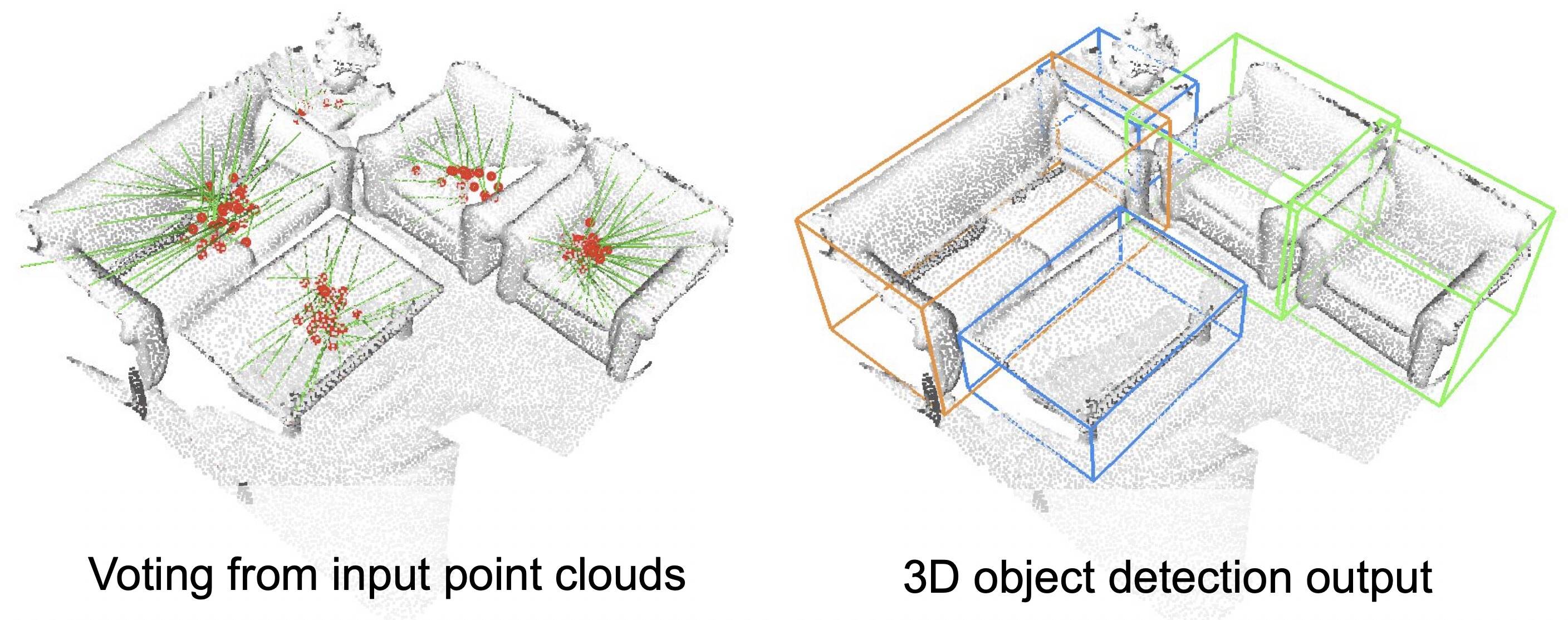
随着自动代理和3D空间扫描系统等尖端技术的不断发展,我们需要推动对象检测机制的进步。在这些情况下,3D场景理解系统需要知道场景中存在什么对象以及它们的位置,从而支持诸如导航之类的高级任务。Facebook通过VoteNet改进了现有系统。VoteNet是为点云量身定制的高精确端到端3D对象检测网络,而它同时获得了ICCV 2019大会的最佳论文提名。与传统系统不同,VoteNet依赖于2D图像信号,而这是首批完全基于3D点云的系统之一。与以前的研究相比,这种方法效率更高,识别精度更高。
Facebook的模型已经开源。据介绍,NoteNet实现了最先进的3D检测,其性能比原来所有的3D对象检测方法都要优秀,比SUN RGB-D和ScanNet中至少增加了3.7和18.4 mAP(平均精度)。VoteNet仅使用几何信息,不依赖标准的彩色图像,其性能优于以前的方法。
VoteNet具有简单的设计,紧凑的模型尺寸,能够实现高效率,全场景的速度约为100毫秒,而且内存占用空间较小。Facebook的算法从深度摄像头获取3D点云,并返回对象的3D边界框,包含语义类。
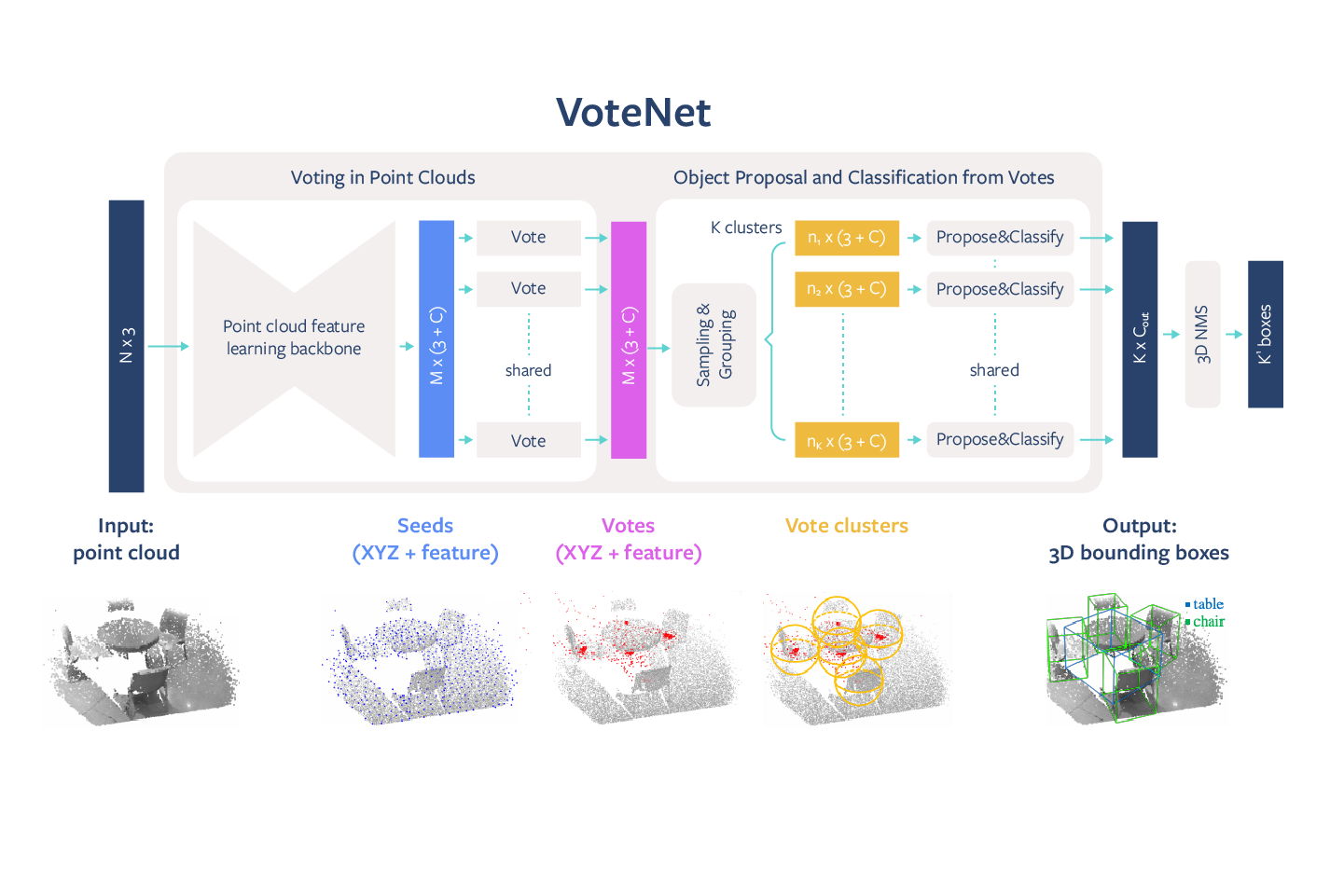
VoteNet架构的示例图
Facebook提出了受经典Hough投票算法启发的投票机制。使用这种方法,Facebook的系统能够生成位于对象中心附近的新点,然后可以将它们进行分组和汇总。利用投票(由深度神经网络进行学习)的基本概念,可以将一组3D种子点投票给对象中心,从而恢复它们的位置和状态。
从自动驾驶汽车到生物医学,随着3D扫描仪的使用情况正在日益增多,通过对3D场景的对象进行定位和分类来实现对3D内容的语义理解非常重要。通过为2D摄像头补充更先进的深度摄像头传感器以进行3D识别,Facebook团队能够捕获任何给定场景的强大视图。借助VoteNet,系统可以更好地识别场景中的主要对象,并支持诸如放置虚拟对象,导航或LiveMap构建等任务。
5. 开发对真实世界有着进一步理解的系统
3D计算机视觉存在大量的开放性研究问题,而Facebook正在尝试通过多种问题假设,技术和监督方法来推动所述领域的进步。随着数字世界的不断发展,3D照片和AR和VR体验等新型产品的兴起,我们需要不断开发出更为智能的系统来更准确理解视觉场景中的对象,并支持与其交互。
这是Facebook AI团队的长期愿景,亦即开发出一个能如同人类般理解世界并与之交互的AI系统。他们表示:“我们一直在致力于缩小物理空间与虚拟空间之间的差距,并实现各个方面的科学突破。我们以3D为重点的最新研究同时可以帮助改善和更好地补充Facebook AI仿真平台中的3D对象推动我们应对在现实世界中进行实验所面临的复杂挑战一样,3D研究对于训练系统如何理解对象的所有视点(即使被遮挡或其他光学挑战)同样很重要。”
Facebook团队最后指出:“当结合诸如触觉感知和自然语言理解等技术时,诸如虚拟助手这样的AI系统可以以更加无缝和有用的方式运行。总而言之,对于我们要构建出能够如同人类般理解三个维度的AI系统,这种前沿研究正在帮助我们朝目标不断迈进。”