研发实战二:用RenderDoc+固定注视点等渲染技术优化Quest应用

系列文章的第二篇博文
(映维网 2019年12月24日)Oculus开发者关系团队的一个主要任务是帮助开发者优化游戏,令其能够有效地支持所有的Oculus硬件。所述团队中的开发者关系工程师克里斯蒂亚诺·费雷拉(Cristiano Ferreira)曾撰文介绍了如何通过RenderDoc来优化你的Quest应用,包括如何轻松将其集成至你的工作流程,相关的基础知识,以及允许你在未来利用这项有用工具的技巧经验。日前,费雷拉通过第二篇系列博文来继续介绍RenderDoc的技巧经验。下面是映维网的具体整理:
在第一篇博文之后我们已经知道应该如何使用RenderDoc,下面我们来看看Oculus Quest硬件和软件堆叠。
1. 如何及如何使用固定注视点渲染
固定注视点渲染(Fixed Foveated Rendering;FFR)是我们操作系统中支持的图形功能,它可以节省像素工作负载的大量时间。FFR仅用单个像素着色器调用在眼图缓冲区粗略的外围区域渲染粗略的像素块。当看向前方时,玩家在很大程度上不会注意到这种粗略的像素。但在某种情况下,根据你的注视点级别,玩家确实会注意到它们。这包括:
- 落在注视点区域内的高对比度纹理
- 落在注视点区域内的纹理硬线
- 延伸至注视点区域的锐利文字
我们支持五个开箱即用的注视点级别,它们可以在不增加负载的情况下每帧进行更新。这种快速切换功能非常有用。例如,若某种情况会出现GPU性能峰值(如玩家即将爆破一堆炸药桶),则可以同一帧抢先提高FFR级别。
这五个注视点级别(映射到枚举)是:
- 0-off
- 1-on(low)
- 2-on(medium)
- 3-on(high)
- 4-on(high top)
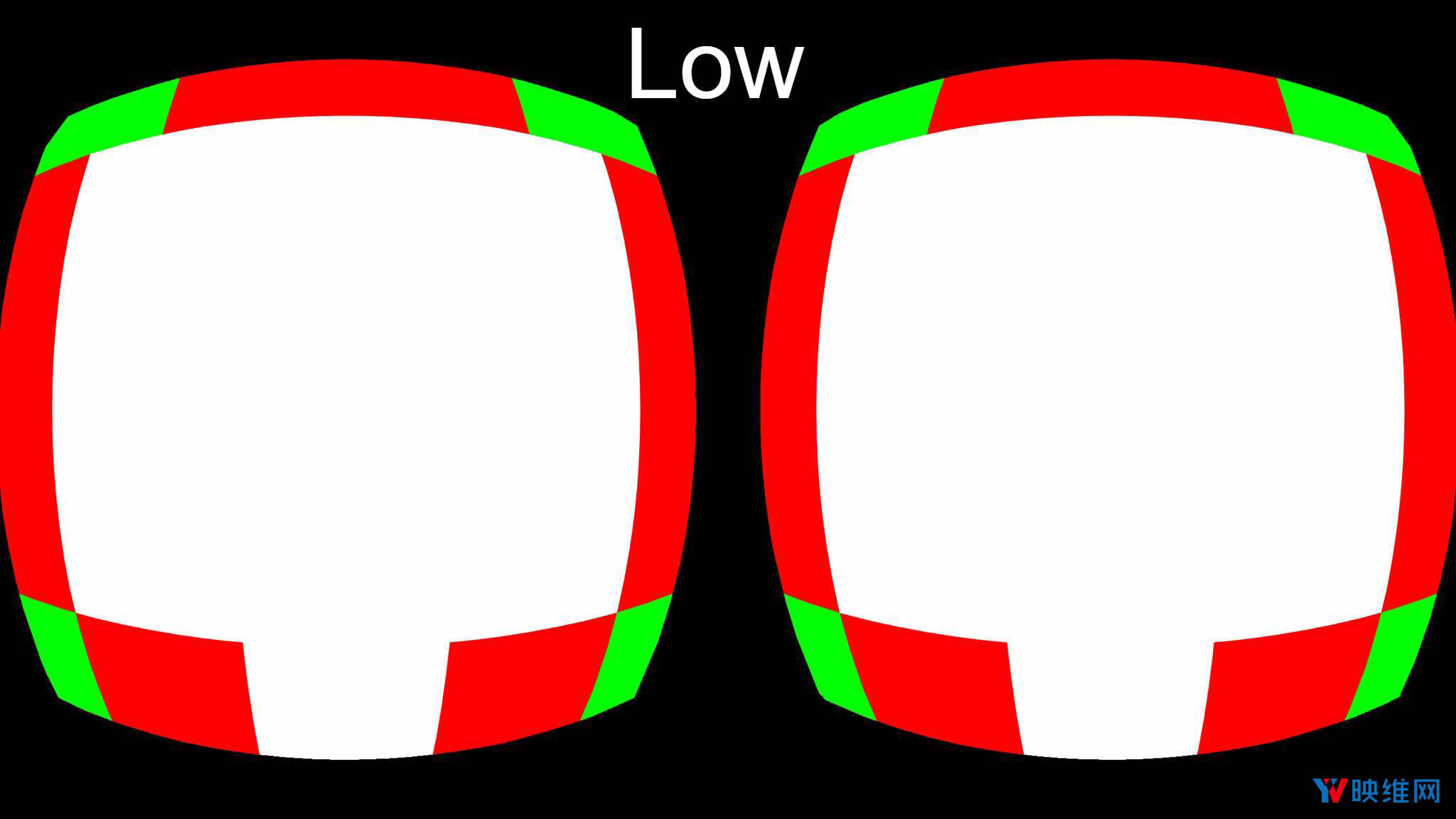
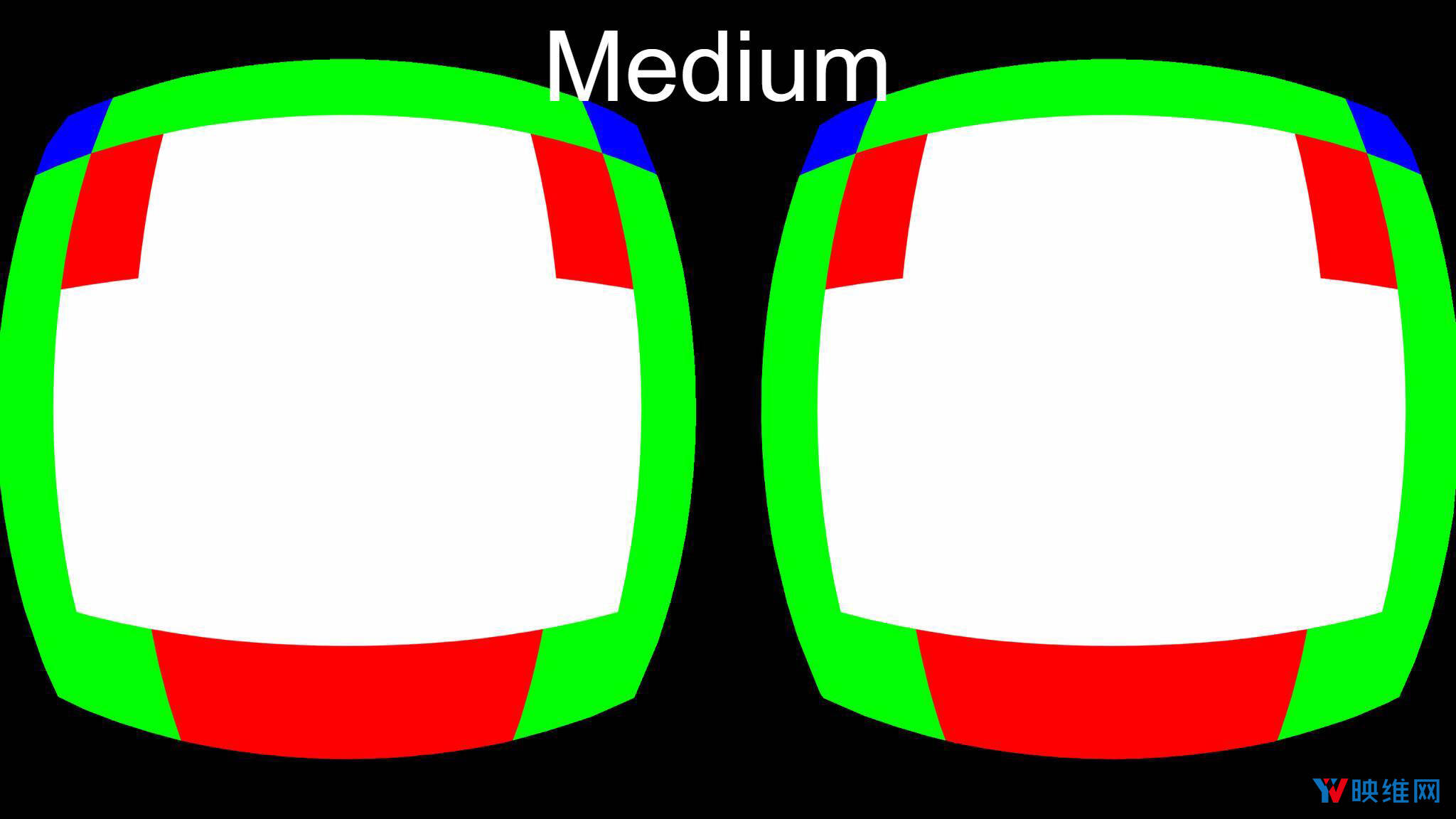
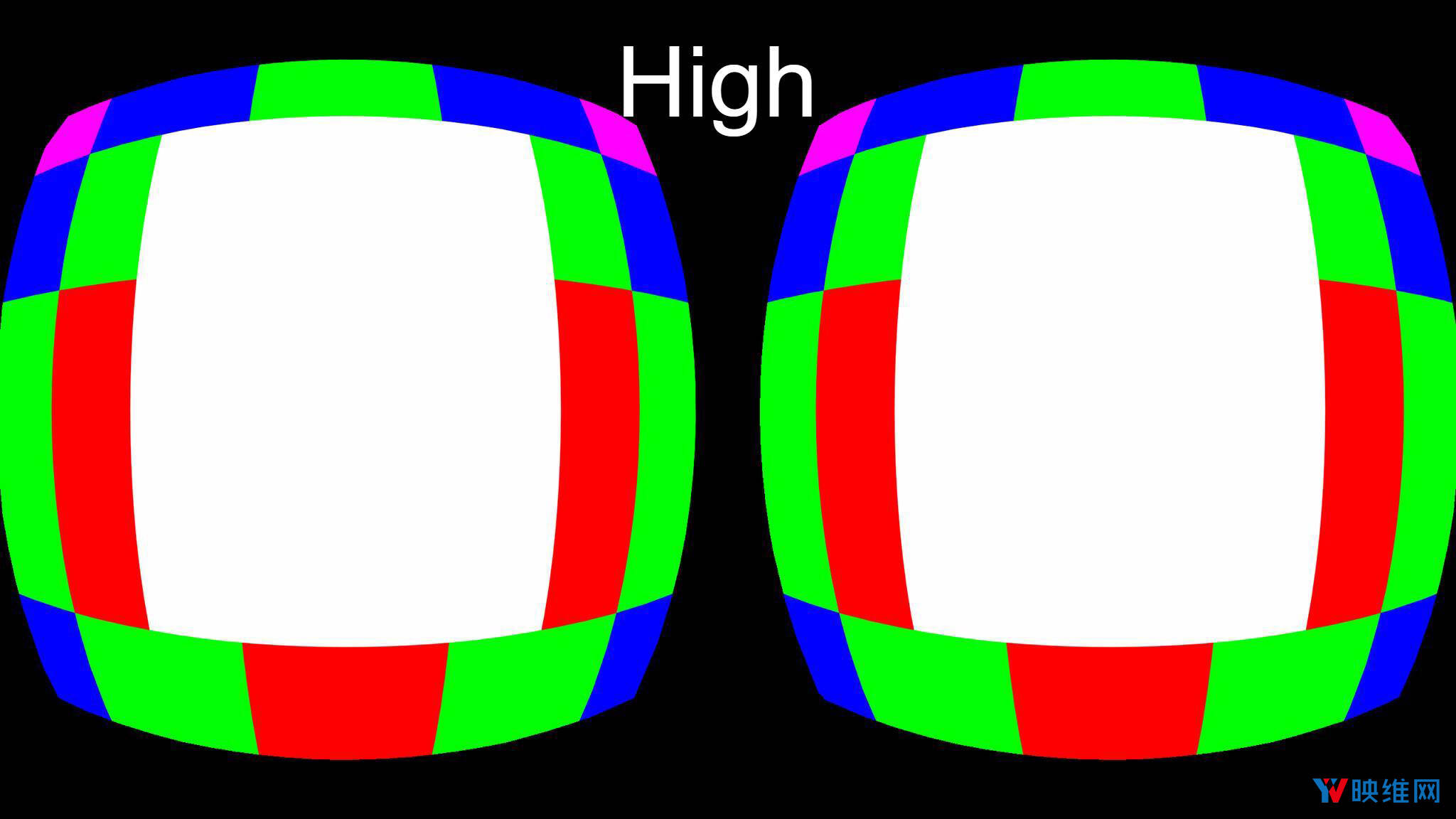

在上图中,白色区域的分辨率为固定,纹理的每个像素将由GPU独立计算。但红色区域仅计算像素的1/2,绿色区域为1/4,蓝色区域将为1/8,洋红色图块则为1/16。当GPU将计算结果存储在通用内存中时,系统将在解析时从计算出的像素中插入丢失的像素。
2. 可编程CPU/GPU频率
为提高续航能力,Oculus Quest操作系统将动态调节或增加CPU/GPU频率,或根据性能启发式帮助更快速地输出帧。尽管操作系统在使用过去的帧定时启发式来确定合适的能耗水平方面非常出色,但没有人比你本人更清楚自己的游戏/应用。所以,我们允许开发者逐帧设置设备的最低CPU/GPU频率。在上述带有炸药桶的情况下,你可以提高CPU和GPU的频率。爆炸可能涉及额外的物理过程,对象激活和绘制调用,这可能会令CPU要求激增,并需要额外的particle billboard,从而耗费额外的GPU性能。在其他情况下,你或许只需GPU正常但CPU增压(反之亦然)。你可以独立切换每个级别。所述API的工作方式与固定注视点渲染的设置非常相似:
- CPU and/or GPU level 0:CPU/GPU频率没有下限
- CPU and/or GPU level 1:将CPU/GPU频率的下限设置为较低
- CPU and/or GPU level 2:将CPU/GPU频率的下限设置为中等
- CPU and/or GPU level 3:将CPU/GPU频率的下限设置为较高
请记住,在选择下限时要遵守“满足需求”的理念,这一点非常重要。你必须考虑续航能力,以便玩家在下次充电之前尽可能长时间地开玩游戏。以level 3全时操作可能会导致设备过热。
3. 什么是多重采样抗锯齿(Multisample Anti-Aliasing;MSAA)
MSAA可以令游戏从良变优。2x/4x MSAA会产生额外的负载,但相对而言,移动设备的计算成本远不及PC。采用某种级别的MSAA,而非将分辨率(渲染比例)保持在原始水平是几乎总是一种首选方案。在启用MSAA的情况下进行渲染时,文本看起来会更加清晰。
4. 基于图块的延迟渲染 vs 即时模式渲染
与我合作的大多数VR开发者都拥有为PC或独显(即时模式渲染)进行开发的丰富经验,但对移动GPU(基于图块的渲染)却没有太多经验。两者之间的主要区别在于,移动GPU已针对带宽进行了优化(最大限度减少了GPU在片段着色期间需要访问的外部存储器数量),从而将功耗降至最低。要实现这一点,在开始任何着色之前,系统会把几何图形全部投影到前面并分配给图块(帧缓冲区的一小部分)。在处理完所有几何图形之后,每个图块都会着色并逐一写入外部存储器。这样一来,单个绘制在“binning”阶段的成本会大大降低。下面简略介绍了每种渲染方法在提交绘制调用后的工作原理:
4.1 即时模式渲染
对于每次绘制调用:
- 对于绘制调用中的每个图元:1.1 为每个顶点执行顶点着色器;2.2为投影图元覆盖的每个片段执行片段着色器。
基于图块的渲染:
阶段1:对于渲染阶段中的每个绘制:
- 对于绘制调用中的每个图元:1.1 为每个顶点执行顶点着色器;1.2. 如果原始图元没有被剔除,则将其附加到与之关联的图块列表中。
阶段2:对于渲染阶段中的每个图块(请注意,单通道游戏/应用的所有几何图形在这一阶段都已投影)
对于图块中的每个图元:
- 对于图元覆盖的每个片段:1.1 为片段执行片段着色器
4.2 基于图块的渲染的应用
外部存储器访问非常缓慢,所以你应该会对可能触发所述情景的任何操作感到厌倦。请思考下面这种种常常予以实现的post-effect:
- 渲染基准传递到临时缓冲区。
- 将渲染目标从临时缓冲区切换到交换链纹理。
- 交换链纹理是最终呈现给显示器的渲染目标(与可能使用不同参数创建的临时缓冲区相反)。
- 为了将post-effect作为一种资源使用,将TempBuffer绑定为输入纹理。
- 执行post-effect。
在这种情况下,GPU会将输入纹理从图块内存写入到外部内存中,从而将其用作输入资源。这同时称为解析。对于Quest头显的原生分辨率,仅向外部存储器写入内容就会花费1ms-1.5 ms的时间来解析纹理(注意:这不包括完成post-effect所需的额外周期)。当以72fps的速度进行渲染时,帧预算将是13.8ms /帧(1000ms/72fps)。所以这项操作大约需要花费总帧预算的大约1/13。另外,当不直接渲染到交换链纹理时,你将不会获得MSAA的视觉优势或FFR的性能优势,因为所述功能仅适用于交换链纹理,不适用于临时缓冲区。
5. 总结
请随时参阅本系列博文的第一篇文章研发实战:如何通过RenderDoc优化Quest应用 。在下一篇文章中,我会介绍将RenderDoc用于Oculus Question游戏/应用时与本文主题相关的关键使用场景和优化技巧。