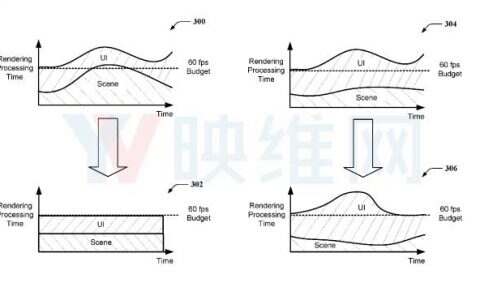
Facebook用神经渲染实现AR/VR全天候穿戴新里程碑!

感知渲染的一个全新里程碑
(映维网 2020年05月16日)Facebook Reality Labs(FRL)致力于构建一个现实世界和虚拟世界能够自由混合,同时提升我们日常生活体验,增加效率和加强彼此之间联结的未来。续航是迈向所述愿景的挑战之一。为了能够实现能够长时间(包括一整天)舒适穿戴的虚拟现实头显和增强现实眼镜,我们必须优化设备的功耗。作为朝构建下一阶段AR/VR系统的一步,这家实验室正努力开发不影响图像质量的情况下显著降低功耗的图形系统。

DeepFovea是FRL为应对这一挑战而开发的数种基于神经网络的方法之一。DeepFovea这个渲染系统利用了最近发明的生成对抗网络(Generative Adversarial Network;GAN)人工智能概念来模拟人类在日常生活中的外围视觉,利用这种感知匹配架构来提供前所未有的图形效率。在测试中,DeepFovea可以将渲染所需的计算资源量减少多达10-14倍,而人眼依然无法注意到任何图像差异。DeepFovea的神经渲染远远超出了目前Oculus产品中的传统注视点渲染系统,能够生成感知上与全分辨率图像别无二致的图像,而需要渲染的像素不到10%。现有的注视点渲染方法需要渲染全分辨率图像一半的像素,所以DeepFovea在渲染需求的数量级进步代表了感知渲染的一个全新里程碑。
FRL最初在2019年11月的SIGGRAPH Asia展示了DeepFovea,而今天,团队公开了关于DeepFovea存储库的完整演示,从而帮助图形研究社区深化对先进感知渲染的探索。

1. DeepFovea:模仿外围视觉,由人工智能驱动
DeepFovea的关键是人眼生理学。当眼睛直视一个对象时,来自所述对象的光子将落在视网膜的中央凹位置,亦即英文中的Fovea。中央凹是视网膜唯一具有高分辨率的区域,而它只占整个视网膜的一小部分。在超过150度的人眼视场中,最高分辨率区域只有3度宽,并且分辨率在距离中心凹的10度范围内将下降一个数量级。我们人类认为自己拥有广阔视场的高分辨率视觉,但这只是因为我们的大脑维系了关于周围环境的模型,填补了缺失的细节,同时将中心凹快速移向到任何目标对象,其速度之快超出了感知的阈值,以至于我们没有意识到自己在那么一瞬间是看不清所述对象。事实上,我们只有一个面积细小的高分辨率感知区域,而我们对周围的一切只有非常模糊的感知。
这不是说外围视觉并不重要。它对于平衡、运动检测和环境感知十分重要,并提示大脑接下来注视点要移动的位置。但它分辨细节的能力非常有限。

DeepFovea使用最少的必要数据量来生成与视网膜分辨率匹配的图像。给定一个稀疏渲染的图像,包含与每个注视点的视网膜分辨率相匹配的可变分辨率,而DeepFovea将能够推断丢失的数据。关键的是,考虑到视网膜分辨率和图像处理特性,这种方法所产生的结果在视觉上与全分辨率图像别无二致。这并不意味着结果是完全相同。如下图例子所示,它们远不及当你用中心凹瞄准对象时的感知分辨率,但对于外围视觉的低分辨率处理,你无法感知到任何差异。
DeepFovea主要是利用GAN来推断缺失的外围信息。FRL通过为数百万个真实视频提供人为降级的外围质量来训练DeepFovea的神经网络。人为降级的视频模拟了外围图像的降级,而基于GAN的设计有助于神经网络根据所有训练视频的统计信息来填充丢失的细节。
结果是,渲染器可以渲染较少数量级的像素,一个60×40度视场的外围的像素密度甚至可以减少多达99%。这大大节省了功耗。得由于DeepFovea和眼动追踪,用户将能够以完全相同的质量感知完全相同的场景。
DeepFovea同时能够确保人眼无法察觉外围视场的闪烁、锯齿和其他视频伪影。
上面视频是一个示例。移动的光标代表着头显用户的注视点在场景移动,而DeepFovea将相应地重建中心凹的视觉效果。请注意输入像素的数量是如何随注视点远离中心凹视觉区域而降低,系统是如何匹配视网膜分辨率,以及DeepFovea是如何以一种像素渲染量不同于全分辨率渲染,但感知上与理想图像别无二致的方式来重构图像。
2. 未来一片光明,且十分高能效
FRL的最终目标是将实时注视点渲染带给能够全天候穿戴的轻便高能效AR/VR设备。DeepFovea演示了其能够渲染比传统渲染器少10%的像素,同时没有出现感知质量损失。这为感知渲染的效率设定一个全新的标准,并标志着朝着前述目标迈出了重要的一步。这种方法不取决于硬件,亦即DeepFovea能够兼容各种AR/VR研究系统。
尽管DeepFovea为AR和VR中的高效绘图提供了一种重要的方法,但这只是超低功耗感知探索的开始。除了研究论文之外,FRL同时发布了DeepFovea演示内容。团队表示,希望这能给志在为感知与神经渲染技术的进步做出贡献的图形与视觉科学研究人员提供一个有用的框架。