SIGGRAPH 2020 AR/VR论文汇总

SIGGRAPH 2020大会收录的论文汇总
(映维网 2020年09月07日)成立于1967年的SIGGRAPH大会一直致力于推广和发展计算机绘图和动画制作的软硬件技术,并已经成为一个集科学、艺术、商业于一身的权威性学术研讨会。今年的大会已经结束,而来自世界各地的研究者和工程师都在这里分享了最新的工作进展。
对于SIGGRAPH 2020大会收录的论文,其中不乏或许可用于虚拟现实/增强现实领域的内容。下面是映维网整理的部分收录论文:
1. MEgATrack: Monochrome Egocentric Articulated Hand-Tracking for Virtual Reality
我们主要提出了用于驱动虚拟现实和增强现实体验的实时手部追踪系统。利用四个鱼眼单色摄像头,系统能够生成精确和低抖动的三维手部。我们主要是通过用于检测手部和估计手部关键点位置的神经网络架构来实现这一点。
手部检测网络能够可靠地处理各种真实世界的环境,而关键点估计网络则利用追踪历史来产生时空一致的姿态。团队同时设计了可扩展的半自动机制,通过手动注释和自动追踪相结合的方式来收集大量不同的ground truth数据。
另外,我们引入了一种追踪检测的方法,在降低计算成本的同时提高了平滑度。优化后的系统在PC端能够以60Hz的速度运行,而移动处理器则是30Hz。
相关论文:MEgATrack: Monochrome Egocentric Articulated Hand-Tracking for Virtual Reality
2. XNect: Real-time Multi-Person 3D Motion Capture with a Single RGB Camera
我们提出了一种使用单个RGB摄像头,并以超过30 fps的速度实时捕捉多人3D运动的方法。它可以成功地在一般场景中运行。我们的方法包含多个阶段。第一阶段是一个卷积神经网络(CNN),它估计二维和三维姿态特征。我们为这个CNN贡献一个新的架构:SelecSLS Net,它使用新颖的选择性长距离和短距离跳转连接来改进信息流,从而在不影响准确性的前提下实现更快的网络;在第二阶段,一个完全连接的神经网络将每个被试的二维姿态和三维姿态特征转化为每个个体的完整三维姿态估计;第三阶段应用时空骨骼模型拟合每个被试的预测二维和三维姿态,进一步协调二维和三维姿态,并加强时间一致性。我们将在一系列具有挑战性的真实场景中演示系统,而它能够以超过30 fps的速度运行,并且达到最先进的精度。
相关论文:XNect: Real-time Multi-Person 3D Motion Capture with a Single RGB Camera
3. Neural Supersampling for Real-time Rendering
我们介绍了一种可以将低分辨率输入图像转换为高分辨率输出的机器学习方法。这种upsampling(上采样)过程利用了神经网络并以场景统计进行训练,从而能够恢复清晰的细节,同时节省在实时应用程序中直接渲染所述细节的计算开销。
对于神经超采样,由运动矢量提供的附加辅助信息特别有效。运动矢量定义了序列帧中像素之间的几何对应关系。换言之,每个运动矢量指向一个亚像素位置,其中在一帧中可见的曲面点可能已经出现在上一帧中。所述值通常是利用计算机视觉方法进行估计,但这种光流估计算法容易出错。相比之下,渲染引擎可以直接生成密集运动矢量,从而为应用于渲染内容的神经超采样提供可靠的、丰富的输入。
4. Gaze-Contingent Ocular Parallax Rendering for Virtual Reality
沉浸式计算机图形系统致力于产生真实的用户体验。当前的虚拟现实显示技术成功地实现了众多感知方面的重要效果,包括透视、视差、运动视差和其他深度线索。在这篇论文中,我们介绍了一种能够精确渲染视差的视觉感知技术。眼睛视差描述了视网膜随眼睛旋转而产生的图像偏移。这种效果是因为眼睛的旋转中心和投影中心不一样。通过设计和进行一系列的用户实验,我们研究了视觉视差渲染的感知含义。具体地说,我们估计了这种效应的感知检测和辨别阈值,并证明在大多数虚拟现实应用中它是清晰可见。另外,我们发现视觉视差渲染提供了一个有效的有序深度提示,并改善了虚拟现实中真实感印象。
相关论文:Gaze-Contingent Ocular Parallax Rendering for Virtual Reality
5. The Eyes Have It: An Integrated Eye and Face Model for Photorealistic Facial Animation
这项研究的主要贡献包括:一个可共同学习,并能够更好地表示注视方向和上面部表情的3D人脸和眼球模型;一种将左右眼注视从彼此和面部其他部分分离开来的方法,从而令模型能够代表前所未见的眼神和表情组合;以及一个用于支持头显摄像头构建精确动画的注视感知模型。定量实验表明,这一方法可以获得更高的重建质量,而定性结果显示所述方法可以大大改善VR虚拟化身的临场感。
相关论文:The Eyes Have It: An Integrated Eye and Face Model for Photorealistic Facial Animation
6. N-dimensional rigid body dynamics
我提出了一个与空间维度无关的刚体动力学公式。我用几何代数来描述刚体的状态和运动方程。使用扩展到nD的碰撞检测算法,我解析了对象之间的碰撞和接触问题。我的实现是4D,但这里描述的技术适用于任何数量的维度。我用一个三维切片来展示这些四维刚体。我允许用户实时操纵这些刚体。
7. Data-driven extraction and composition of secondary dynamics in facial performance capture
表达性对象的表达捕捉,特别是高空间分辨率获得的面部表现,其不可避免地会包含一些由于惯性效应和弹道运动而产生的次级动态效果。在大多数自然捕捉环境中,演员在表演时能够自由移动,而不是固定在特定的位置。通常,所述的次级动态效果并不需要,因为捕捉到的面部表情通常会重新定位到不同的头部运动,有时甚至是完全不同的角色。在这两种情况下,我们应该移除捕捉到的动态效果,并添加新的二级效果。本文提出了这样一个假设:对于一个高度约束的弹性介质(如人脸),这些次级惯性效果主要是由于骨结构(头骨和下颌骨)运动产生。我们的研究旨在计算和描述捕捉到的动态面部表现之间的差异。这可以用来减去在捕捉过程中由于无意运动而产生的次级动力,或者在准静态表演的基础上合成这样的效果,从而模拟演员身体和头骨的动态运动。
相关论文:Data-driven extraction and composition of secondary dynamics in facial performance capture
8. ARAnimator: in-situ character animation in mobile AR with user-defined motion gestures
创建与真实环境紧密交互的虚拟AR角色动画十分有趣,但非常困难。现有的系统采用视频透视的方式来间接控制移动AR中的虚拟角色,而这使得与真实环境的紧密交互变得不太直观。在这项研究中,我们使用一个具有AR功能的移动设备来直接控制位于真实环境中的虚拟角色位置和运动。我们发现,基于SVM的学习方法可以从移动设备的运动数据中获得相当高的手势分类精度。我们提出了一个ARAnimator,它允许新手用户和休闲用户通过一个支持AR的手机直接表示一个虚拟角色,并使用设备的运动手势来控制其在AR场景中的动画,然后通过视频透视界面进行动画预览和交互式编辑。实验结果表明,利用ARAnimator,用户可以轻松地创建与不同真实环境紧密交互的角色动画。
相关论文:ARAnimator: in-situ character animation in mobile AR with user-defined motion gestures
9. The design and evolution of the UberBake light baking system
我们描述了UberBake的设计和发展。UberBake是一个由动视开发的全局照明系统,它支持有限的照明变化以响应特定的玩家交互。我们不依赖完全动态的解决方案,而是使用传统的静态照明烘焙管道,并通过一组小功能对其进行扩展,从而使得我们能够在运行时以最小的性能和内存开销动态更新预计算的照明。这意味着我们的系统能够支持从高端PC到前代游戏机的各种系统。特别地,我们展示了如何有效地预计算由于单个照明的启用和禁用,以及大门打开和关闭而引起的照明变化。
相关论文:The design and evolution of the UberBake light baking system
10. Tactile Rendering Based on Skin Stress Optimization
我们提出了一种呈现虚拟触摸的方法,从而使得位于用户皮肤的触觉设备所产生的刺激与虚拟环境模拟中的计算刺激相匹配。为了实现这一点,我们采用了一种新的优化算法来解决从皮肤刺激到设备配置的逆映射问题。在所述算法中,我们使用设备皮肤模拟模型来估计渲染的刺激,通过将摩擦状态的计算与设备配置的优化解耦而有效地考虑了轨迹相关的影响,同时使用设备皮肤模型的神经网络近似来加速计算。概括而言,我们可以实时触觉渲染丰富的交互。
11. Directional sources and listeners in interactive sound propagation using reciprocal wave field coding
常见的声源会表现出强烈的频率和方向依赖性。当在复杂的环境中传输时,它们的各向异性辐射场在到达方向敏感的听者之前会经历散射、衍射和遮挡。我们提出了第一个基于波的交互式听觉化系统,它可以对一般场景中的声波场进行编码和呈现。我们的方法在自由移动和旋转的声源呈现方向效应,并且支持任何列表的源方向性函数和头相关传递函数。对于各种环境和源类型,我们演示了依赖于详细场景几何体的令人信服的效果。
12. A Scalable Approach to Control Diverse Behaviors for Physically Simulated Characters
具有广泛自然外观和实际行为的人类角色将有助于构建引人入胜的交互式体验。在这篇论文中,我们提出了一种旨在适应大量异类行为的技术。通过将一个运动参考库划分为类似运动的簇,我们可以构造能够在所述簇中再现运动的模拟版本。我们的系统通过由8小时动捕数据构建的运动图所产生的运动进行训练,并包含了一系列不同的行为,如跳舞、空手道动作、手势、行走和跑步。
相关论文:A Scalable Approach to Control Diverse Behaviors for Physically Simulated Characters
13. High Resolution Étendue Expansion for Holographic Displays
全息显示器可以创建高质量的三维图像,同时保持适合头戴式虚拟现实和增强现实系统的小尺寸。然而,基于空间光调制器中像素的数量,全息显示器的光通量有限,从而就造成了视窗和视场之间的折衷。
我们在这项研究中引入了新的算法,以空间光调制器的固有分辨率支持密集的、真实的图像。与基线方法相比,峰值信噪比提高了20dB。我们提出空间和频率约束来优化人的感知性能,并通过仿真和初步的台式样机对性能进行了表征。我们进一步展示了在多个深度生成内容的能力,并提供了一种将台式原型小型化为类似太阳镜的外形的途径。
相关论文:High Resolution Étendue Expansion for Holographic Displays
14. Exertion-aware path generation
我们提出了一种新的路径生成方法,而所述方法可以用来实现高度逼真的沉浸式虚拟现实应用。在给定一个地形作为输入,我们基于优化的方法能够自动生成可行的路径,并允许用户在虚拟现实中进行自行车骑行锻炼。所述方法考虑了路径生成过程中的总工作量和路径难度的感知程度等特性。为了验证我们的方法,我们将其应用于在各种地形上生成具有不同施加目标和约束的路径。为了进行我们的用户研究,我们建造了一辆运动自行车。我们的用户研究结果显示,与传统的锻炼方法相比,用户在使用我们生成的路径进行锻炼时更令人愉快。他们在自行车道上的能量消耗同时符合指定的目标,从而验证了我们方法的有效性。
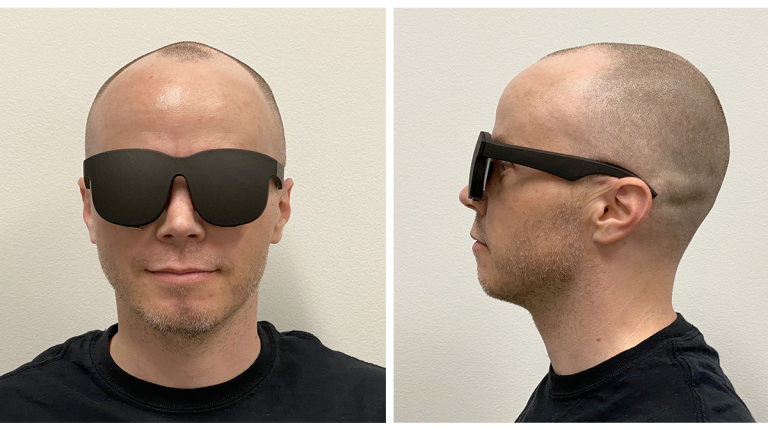
15. Holographic Optics for Thin and Lightweight Virtual Reality
我们提出了一种结合了全息光学元件和基于偏振的光学折叠的全新近眼显示器,而这一方法可用于开发未来的太阳镜式VR硬件。两种方法的结合有助于实现尽可能细薄的光学元件,同时最有效地利用空间。具体而言,设备仅采用细薄平面薄膜作为光学元件,并实现了小于9毫米的显示器厚度,同时支持与当今消费类虚拟现实产品相当的视场。这项研究同时展示了更优视觉性能的前景:激光照明用于为虚拟现实显示器提供更广泛的颜色范围,并且在将分辨率扩展到人类视觉极限方面取得了进展。
相关论文:Holographic Optics for Thin and Lightweight Virtual Reality
16. Towards occlusion-aware multifocal displays
人类视觉系统使用大量线索来感知深度,包括视差、调节、运动视差和遮挡。多焦点显示器是满足视觉调节提示的经典方法之一,它将虚拟内容放置在多个焦平面之上,而每个焦平面的深度不同。然而,靠近眼睛的焦平面上的内容不会遮挡远处的内容,这会恶化遮挡线索,并且由于散焦模糊泄漏而降低深度不连续处的对比度。本文使用了新的ConeTilt算子来实现了遮挡感知的多焦点显示。我们发现,对于具有相对简单遮挡配置的场景,ConeTilt可以提供与物理遮挡相同的效果。我们证明了ConeTilt可以很容易地用纯相位空间光调制器来实现。使用一个实验室原型,我们展示的结果证明了遮挡线索的存在和深度边缘显示对比度的增加。
17. Immersive light field video with a layered mesh representation
我们研发了一个低成本的装置来录制沉浸式光场视频。所述装置由46个安装在轻质亚克力圆顶的运动相机组成。利用由同一谷歌研究小组成员在2019年开发的机器学习算法DeepView,我们将来自每台相机的视频流组合成一个场景的3D表示。论文同时介绍了一种全新的“分层网格”表示,它由一系列具有半透明纹理的同心层组成。通过从后到前地渲染所述层,场景将能变得生动逼真。在以前,合成相机一开始未能捕获的视点是一个非常困难的问题,但所述新方法解决了这一痛点,并允许用户在探索光场视频内容时自由地转动头部。另外,所述系统能够在压缩光场视频的同时保持原始的视觉质量,并使用传统的纹理贴图和广泛支持的视频编解码器来实现。
相关论文:Immersive light field video with a layered mesh representation
18. HeadBlaster: a wearable approach to simulating motion perception using head-mounted air propulsion jets
我们介绍了一种新颖的可穿戴技术HeadBlaster,它可以对头部施力并刺激前庭和本体感感觉系统,从而创造运动知觉。与倾斜身体的运动平台相比,HeadBlaster更接近真实运动中横向惯性力和离心力的感受,从而提供更持久的运动感受。另外,由于HeadBlaster只驱动头部而不是整个身体,它消除了约束用户运动的机械运动平台,从而提高了用户的移动性,并可以房间规模VR体验。我们设计了一个可穿戴的头部喷射系统:6个空气喷嘴集成到一个虚拟现实头显中,并使用压缩空气射流提供持久的横向推进力。通过控制多个空气喷射,它能够在360度内产生横向加速度的感觉。为了量化头部运动、感知加速度的持续性和可检测力的最小水平,我们进行了一系列的感知和人为因素研究。然后,我们通过两个虚拟现实应用程序探索了HeadBlaster的用户体验。研究结果表明,与运动平台相比,HeadBlaster提供了更长的感知加速度持续时间。它同时显著提高了真实感和沉浸感。另外,它可以与运动平台结合使用,从而进一步增强用户体验。